DISCOVER PROJECT
From alerts to investigation in multi-domain networks
COMPANY
VMware
YEAR
2023
ROLE
Staff UX Designer — Led experience strategy and investigation workflow design
EXPERTISE
UX strategy, information architecture, interaction design, prototyping, design systems, AI/ML observability
view full CASE STUDY
Telco Cloud Service Assurance shifted operator behavior from reacting to alarm volume to converging on shared root cause. By making causal relationships and evidence legible, the platform enabled faster alignment across teams and reduced time spent validating whether the system was correct.
Role
Owned experience strategy for real-time monitoring, topology-driven correlation, and root cause investigation. Defined investigation flows, interaction models, and experience principles governing how automated insights are presented to operators in high-severity environments.
Process / Scope
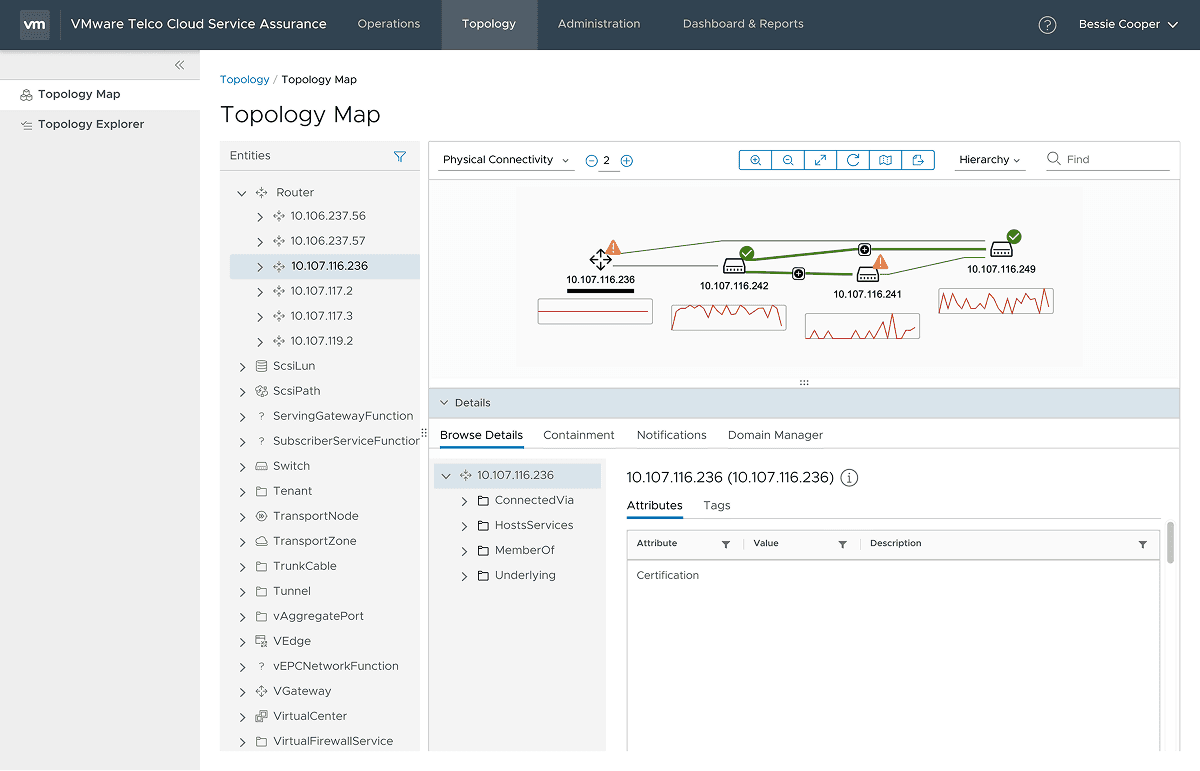
Enterprise telecom service assurance across physical, virtual, and service layers Designed for multi-domain environments spanning transport, virtualized network functions, and service impact layers, supporting large-scale service provider and hybrid network operations. Shipped across TCSA 2.1–2.4; aligned with telco portfolio milestones.
Why This Work Was Needed
Traditional assurance tools surfaced large volumes of disconnected alerts, forcing operators to manually construct causality under time pressure. This created operational drag, increased misdirected remediation, and reduced trust in automation. The redesign addressed the cognitive and organizational cost of fragmented interpretation by making correlation and system reasoning visible. This created tension between leadership pressure to reduce mean time to resolution and the operational risk of confidently acting on incomplete or misleading signals.
Solution
Telco Cloud Service Assurance became a unified investigative surface. Topology, service impact, and causal correlation were integrated so operators could work with causal chains instead of flat alerts. This enabled teams to understand how failures propagated across domains and align on likely cause more quickly. The product shifted from monitoring symptoms to supporting shared reasoning.
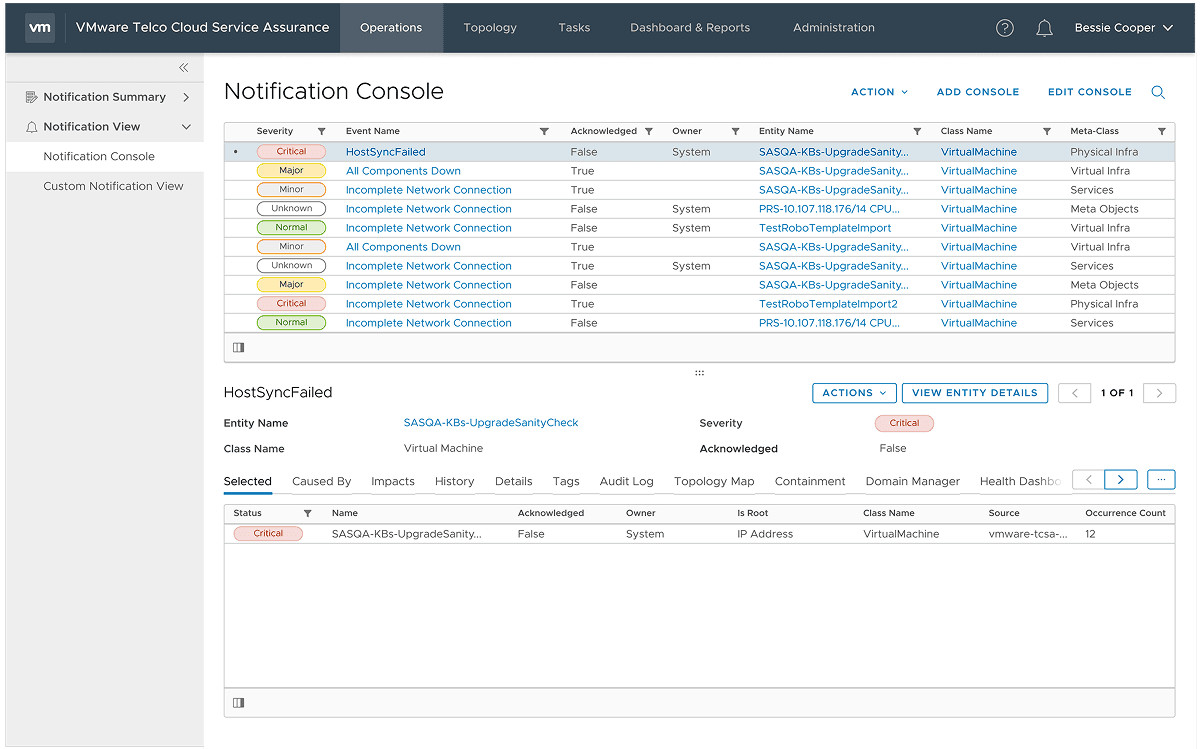
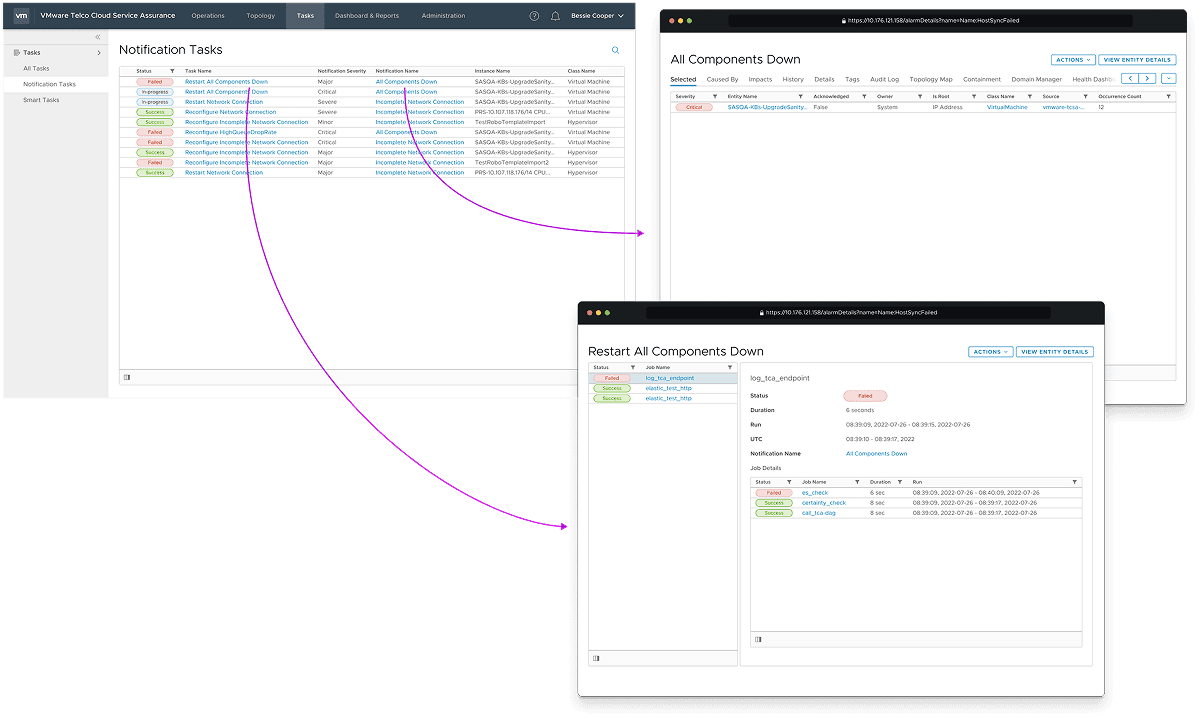
Results
Operators converged faster on true underlying causes, reduced false escalations, and developed greater trust in automated correlation because system reasoning was visible. This reduced symptom-driven escalation and improved cross-team alignment during live incidents. The platform evolved from a monitoring tool into infrastructure for operational sense-making.
view full CASE STUDY